Time Series Modeling - Sunspot Activity
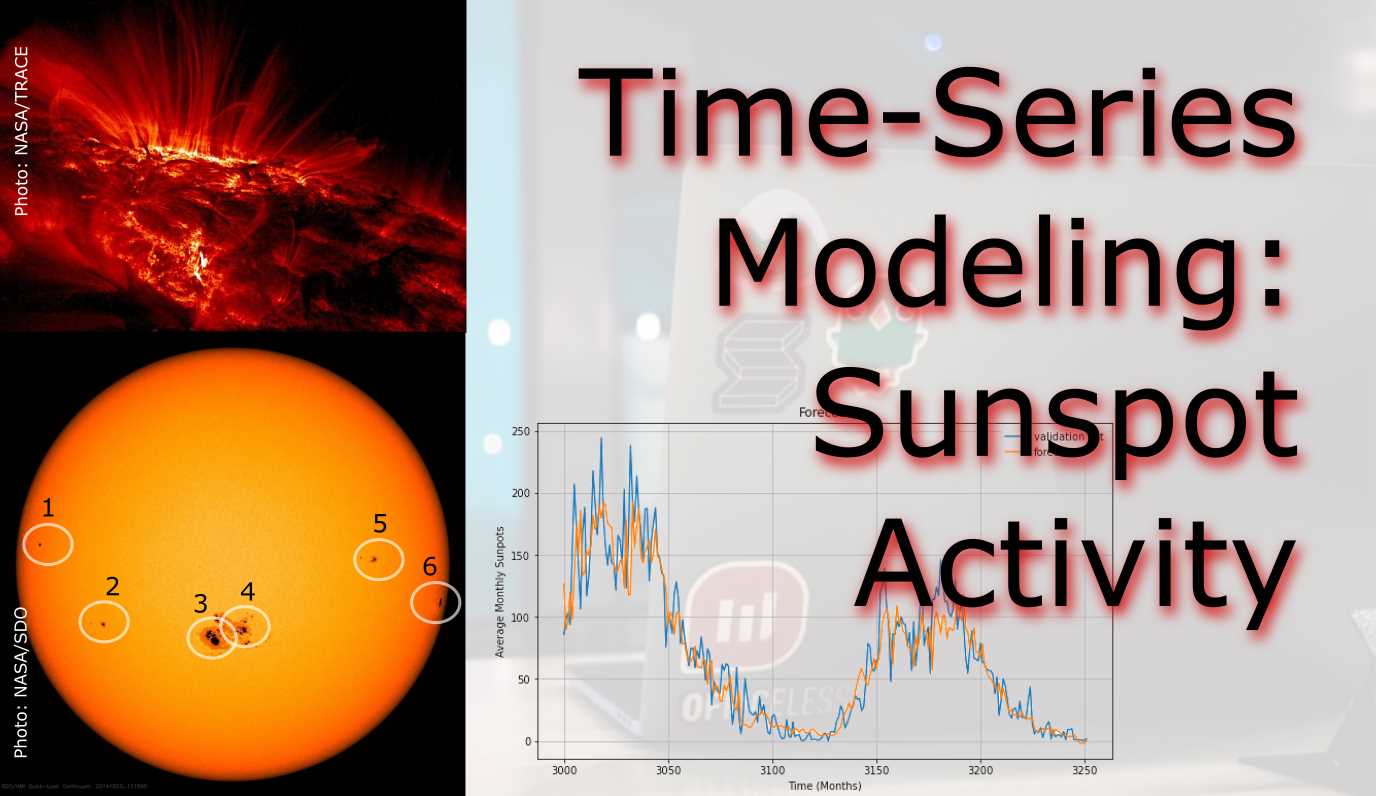
Sunspots have a scientific record reaching back to 1749
- Introduction
- Dataset
- Methodology
- Module Imports
- Step 1: Download, Unzip, Load
- Step 2: Read csv and Explore
- Step 3: Pre-Processing
- Step 4: Train for Learning-Rate Optimization
- Step 5: Train with Optimized Learning Rate
- Step 6: Forecasting and Evaluating
Introduction
For this project we will examine making time series predictions using sunspot records. Sunspots are dark spots on the sun, associated with lower temperature but also marked by intense magnetic activity. They play host to solar flares and hot gassy ejections from the sun’s corona.
As the Sun moves through its natural 11-year cycle, in which its activity rises and falls, sunspots rise and fall in number, too. NASA and NOAA track sunspots in order to determine, and predict, the progress of the solar cycle — and ultimately, solar activity.
Currenly, in 2019/2020, sunspots are at the end of the cycle, but are expected to pick up soon.
Forecasting this dataset is challenging because of high short-term variability as well as long-term irregularities evident in the cycles. For example, maximum amplitudes reached by the low frequency cycle differ a lot, as does the number of high-frequency cycle steps needed to reach that maximum low-frequency cycle height.
Methodically, this project will focus on how how to apply deep learning to time series forecasting with LSTMs, and implement learning rate optimization for the lowest loss possible.
Have a look at the notebook here.
Dataset
The data used the most up-todate monthly version that contains monthly averages. It contains 270 years worth of data (from 1749 through 2019) and a total of 3252 samples (months). The data can be found here at Kaggle.
Methodology
A Recurrent Neural Network (RNN) is a type of neural network well-suited to time series data. RNNs process a time series step-by-step, maintaining an internal state from time-step to time-step.
In this project, we use an RNN layer called Long Short Term Memory (LSTM).
An important constructor argument for all keras RNN layers is the return_sequences argument. This setting can configure the layer in one of two ways.
Module Imports
import kaggle #api token file required
import os
import shutil
import zipfile
import pandas as pd
import csv
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
Step 1: Download, Unzip, Load
Most conveniently use the Kaggle API for downloading this challenge data set. You will need a Kaggle account and save the API credentials in a specific folder.
!kaggle datasets download -d robervalt/sunspots
# target folder
local_zip = f'{os.getcwd()}\\Data\\sunspots.zip'
# cut and paste
shutil.move(f'{os.getcwd()}\\sunspots.zip', local_zip)
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall(f'{os.getcwd()}\\data')
zip_ref.close()
Step 2: Read csv and Explore
Pandas dataframes allow for very neat, tabular representation of csv files.
pd.read_csv(f'{os.getcwd()}\\data\\sunspots.csv')

However, for the remainder of the project we will use Numpy arrays. The lines of the csv are read line-by-ine with an iterator. The column headers need to be skipped. We need the running index as time monthly steps and the sunspot counts. Note that the data gets cast into integer and floats.
time_step = []
sunspots = []
with open(f'{os.getcwd()}\\Data\\sunspots.csv') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader) # the next() function skips the first line (header) when looping
for row in reader:
sunspots.append(float(row[2]))
time_step.append(int(row[0]))
For plotting up data later on, define a function that accepts time steps and sun spot values.
def plot_series(time, series, format="-", start=0, end=None, label=None):
myplot = plt.plot(time[start:end], series[start:end], format, label=label)
plt.xlabel("Time (Months)")
plt.ylabel("Average Monthly Sunpots")
if label != None:
plt.legend()
plt.grid(True)
Before plotting, the data gets converted to Numpy arrays.
series = np.array(sunspots)
time = np.array(time_step)
plt.figure(figsize=(15, 9))
plot_series(time, series)

Step 3: Pre-Processing
Now that the data set is available as a single chunk of 3251 samples, we want to sub-divide it into a train set and a viladation set. With ther split time set at 3000, the largest chunk will go into training.
split_time = 3000
time_train = time[:split_time]
x_train = series[:split_time]
time_valid = time[split_time:]
x_valid = series[split_time:]
# the window size is important for training results
window_size = 30
batch_size = 32
shuffle_buffer_size = 1000
Graphing helps us understanding the split better.
plt.figure(figsize=(15, 9))
plt.title("Train/Test Split")
plot_series(time_train, x_train, label="training set")
plot_series(time_valid, x_valid, label="validation set")

For training a time series, the algorithm takes in a snippet of samples and predicts the next point coming afterwards. The windowing helper-function does this with our desired window size. The longer the window size, the more history can be learned to forecast the value that comes next. The window_size value influences the model performance and requires optimizing for the sunspot cycles.
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
series = tf.expand_dims(series, axis=-1)
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size + 1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size + 1))
ds = ds.shuffle(shuffle_buffer)
ds = ds.map(lambda w: (w[:-1], w[1:]))
return ds.batch(batch_size).prefetch(1)
To demonstrate how the windowed_dataset function and the window_size parameter are slicing the data set, have a closer look at the graph below.
window_size = 64
def plot_split(array, window_size):
number_windows = len(array) // window_size + 1
return np.array_split(array, number_windows, axis=0)
plt.figure(figsize=(15, 9))
plt.title("Windows")
for series_window,time_window in zip(plot_split(series,window_size), plot_split(time,window_size)):
plot_series(time_window, series_window)

Step 4: Train for Learning-Rate Optimization
Next task is finding a learning rate that delivers the least loss. With a callback that contains a Learning Rate Scheduler, the learning rate is increased sucessively over the 100 epochs. The model design itself will remain the same later. Fisrst, a 1D-convolutional filter with a width of 5 (2 samples before, two after the selected sample) and then two LSTM layers do the sequence learning work. Two dense layers and an output layer (1 neuron) make up the rest of the network.
The Huber loss makes it necessary to work with larger outputs. That is why the lambda layer was chosen to multiply the output layer’s results by 400. I decided to use the Mean Absolute Error (MAE) as a metric that does not punish for large errors as severely as the Mean Squared Error (MSE)
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
window_size = 64
batch_size = 256
train_set = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)
print(train_set)
print(x_train.shape)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=5,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400)
])
lr_schedule = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-8 * 10**(epoch / 20))
optimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(train_set, epochs=100, callbacks=[lr_schedule], verbose=0)
All the epoch’s metrics are saved in the history variable and can be visualized. The graph helps us find a learning rate with lowest loss and assure it is in an area of low volatility. A learning rate of 10e-5 is a safe pick.
# pick lr from graph
plt.semilogx(history.history["lr"], history.history["loss"])
plt.axis([1e-8, 1e-4, 0, 60])
plt.title('Learing Rate Optimization')
plt.xlabel("Learing Rate")
plt.ylabel("Loss")

Step 5: Train with Optimized Learning Rate
Plug in the new learning rate, remove the learning rate scheduler callback, and increase epochs. The network design remains the same as before.
tf.keras.backend.clear_session()
tf.random.set_seed(51)
np.random.seed(51)
train_set = windowed_dataset(x_train, window_size=60, batch_size=100, shuffle_buffer=shuffle_buffer_size)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=5,
strides=1, padding="causal",
activation="relu",
input_shape=[None, 1]),
tf.keras.layers.LSTM(60, return_sequences=True),
tf.keras.layers.LSTM(60, return_sequences=True),
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1),
tf.keras.layers.Lambda(lambda x: x * 400)
])
optimizer = tf.keras.optimizers.SGD(lr=1e-5, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(train_set,epochs=500, verbose=0)
Visualize the training progress.
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
loss = history.history['loss']
epochs = range(len(loss))
# full graph
plt.plot(epochs, loss, 'r')
plt.title('Training loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss"])
plt.figure()
# zoomed graph
zoomed_loss = loss[200:]
zoomed_epochs = range(200,500)
plt.plot(zoomed_epochs, zoomed_loss, 'r')
plt.title('Training loss (zoomed)')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(["Loss"])
plt.figure()

Step 6: Forecasting and Evaluating
Define a helper function for forecasting, call it, and plot a zoom-in of one of the cycles. Here, we see the last sun-spot cycle and how the model (orange) at least visually matches the training/validation (blue) data quite well.
def model_forecast(model, series, window_size):
ds = tf.data.Dataset.from_tensor_slices(series)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecast
rnn_forecast = model_forecast(model, series[..., np.newaxis], window_size)
rnn_forecast = rnn_forecast[split_time - window_size:-1, -1, 0]
plt.figure(figsize=(10, 6))
plt.title("Forecast")
plot_series(time_valid, x_valid, label='validation set')
plot_series(time_valid, rnn_forecast, label='forecast')

Of course, a quantitative comparison is more accurate in describing the model’s fit to the validation set.
print('Mean Absolute Error (MAE): ',tf.keras.metrics.mean_absolute_error(x_valid, rnn_forecast).numpy())
Mean Absolute Error (MAE): 14.52463
This has been a long post, and necessarily will have left a lot of questions open, first and foremost: How do we obtain good settings for the hyperparameters (learning rate, number of epochs…)? How do we choose the length of the LSTM? Or even, can we have an intuition how well LSTM will perform on a given dataset (with its specific characteristics)? All questions to be tackled in the future. GitHub’s initiative to preserve open-source code If you are a GitHub user like me, you might have received a new badge on GitHub called Arctic Code Vault Contributor with a notification as in the cover picture above. The badge is testament that your code in public repos was backed up for really, really, really, really long time to come. Microsoft, which acquired GitHub for $7.5 billion in 2018, is preparing itself and GitHub for the apocalypse. As a reaction, Microsoft and GitHub recently launched a project called “GitHub Archive Program” along with the GitHub Arctic Code Vault. The vault will be co-located with the Arctic World Archive (AWA), a disused coal mine on Svalbard Archipelago north of Norway. The major purpose of this project is to conserve major open-source contributions for future generations by storing them in an archive and save them for a thousand years. Alas, GitHub and Microsoft will not be the sole tenant of AWA. The digitized art and documents from the Vatican, various illustrious meuseums, governments, and companies will have to share space in the mine. The progess was largely orchestrated by piql. Digital file formats are fast-lived and many common digital storage devices have to be replaced after few years (DVDs and BluRays do physically degrade over time!). Tape, SSD, or HDDs neither offer longevity. Instead, the code was printed onto film reels, which perfectly aligns with GitHub’s objectives. The cold permafrost on Svalbard will help slow down the degradation of the film reels. In fact, the coal mine is very close to the Svalbard Global Seed Vault, which has very similar goals, but for rare plant seeds that may get marginalized by modern genetically modified plants. In short: everything public on GitHub. At first the collection includes the source code for the Linux and Android operating systems; the programming languages Python, Ruby, and Rust; web platforms Node, V8, React, and Angular; cryptocurrencies Bitcoin and Ethereum; AI tools TensorFlow and FastAI; and many more. Furthermore, every public repository that was publicly available as of February 2, 2020 was copied and went into storage. That likely includes you. Finally, the question that bugs me is: If you deleted your repo, can you book a flight to Svalbard and get a copy of your backup? :) Official Link: https://archiveprogram.github.com/ Implement an NLP model with a chat GUI A chatbot is smart code that is capable of communicating similar to a human. Chatbots are used a lot in customer interaction, marketing on social network sites and instantly messaging the client. There are two basic types of Natural Language Processing (NLP) chatbot models based on how they are built: Retrieval based. A retrieval-based chatbot uses predefined input patterns and responses. It then uses some type of heuristic approach to select the appropriate response. It is widely used in the industry to make goal-oriented chatbots where we can customize the tone and flow of the chatbot to drive our customers with the best experience. Generative based models are not based on some predefined responses. They are based on seq 2 seq neural networks. It is the same idea as machine translation. In machine translation, we translate the source code from one language to another language but here, we are going to transform input into an output. It needs a large amount of data and it is based on Deep Neural Networks (DNN). We are going to build a chatbot using deep learning techniques following the retrieval-based concept. The chatbot will be trained on the dataset which contains conversation categories (intents), patterns, and responses. The model uses a Deep Neural Network with a single hidden layer to classify which category the input message belongs to and then the chatbot will select a random response from the list of responses, which have similar meaning. Topics the chatbot will be helpful with is helping doctors/patients finding (1) Adverse drug reaction, (2) Blood pressure, (3) Hospitals and (4) Pharmacies. It may be used on websites pertaining to hospital, pharmaceutical online stores etc. or modified to fit completely different purposes. Furthermore, this is just a prototype whose functionality can be greatly expanded in topics it can reply to, depth of conversation, answer variert and so on. The training set and DNN for chatbot inference was created in a separate Jupyter notebook. The model used data from the intents.json file, which contains: Files generated in that notebook are: If you want to follow along and try it out yourself, download the Jupyter notebook containing all the steps shown below. Check if your environment has all the packages installed. The necessary data files for this project are available from this folder. Make sure the paths in the notebook point to the correrct local directories. And of course, you will need to install all the Python packages if you do not have all of them yet. Give it a go and talk with the chatbot yourself! Call all the libraries we need for this project Loading words, model, and replies into objects. For class prediction, we need to provide input in the same way as we did for training. These helper functions perform text preprocessing when the user clicked “Send” and then predict the class. After predicting the class (tag) of the user input, these functions select a random response from the list of intent (i.e. from intents.json file). Code for the Graphical User Interface. The GUI uses the tkinter library, which is an Python interface to the Tk GUI toolkit. Tkinter is Python’s de-facto standard GUI. Tasks of the GUI are: (1) Accept the input message from the user and then (2) use the helper functions to get the response from the bot and then (3) display everything in a window. Here, everything comes together. The different objects on the screen are defined and what functions are executed when they are interacted with. The ChatLog text field’s state is always set to “Normal” for text inserting and afterwards set to “Disabled” so the user cannot interact with it. A drowsiness detector to try out on yourself For this ML/DL project, we will implement a relatively simple drowsiness-detection tool. Drowsiness detection can be done by measuring if someone’s eyes were closed longer than blinking and may be a life-saver in many instances. For example while driving a vehicle for long hours or at night (Wikipedia: Driver drowsiness detection, NYTimes: Sleepy Behind the Wheel? Some Cars Can Tell). Other use cases are more recent applications such as virtual school classes. In either case, we hope people are wide awake during these activities. I will show how to implement a camera system that watches a person and can tell if they are falling asleep. The most accute signs for this are prolonged periods of closed eyes. For the model here I will first use a Haar Cascade object identifier to find face and eyes in real-time footage. From an incoming frame, the eyes will be cropped and fed into a Convolutional Neural Netowk (CNN) model for inference. If closed eyes were predicted for several consecutive frames, a warning chime will sound. When eyes are predicted open again, everything is supposed to go back to normal. Give it a go! Dataset creation. To create the DNN dataset, a script was written that captures eyes from a camera and stored them on local disk. They were labeled “Open” or “Closed”. The data was manually cleaned by removing bad and redundant images. The dataset comprised ~7,000 images of people’s eyes under different lighting conditions. Sorry, this is too big for GitHub. Training. Next, a Deep Neural Network (DNN) model was trained to classify open and closed eyes. See file “Drowsiness_detection_CNN_pre-train.ipynb” and the the final weights and model architecture file “cnnCat2.h5”. Object Detection. The Haar Cascade (example in OpenCV) finds landmarks in image frames and cuts them out. The Haar Cascade algorithm produces similar results as the newer YOLO object detection using image convolution filters but instead uses kernel computation. Kernel computation is very similar to YOLO’s convolution filters. Different kernels are tuned for different landmarks and can be loaded as needed. The “cascade” part of the algorithm is used to narrow down features to the wanted areas and save computation. The kernels we will use here are set to detect eyes and face. Many pre-tuned kernels are shared by OpenCV for different purposes and objects. Link to OpenCV’s kernel repo. If you want to follow along and try it out yourself, download the Jupyter notebook. Check if your environment has all the packages installed. The necessary data files for this project are available from this folder. Make sure the paths in the notebook point to the correrct local directories. And of course, you will need a video camera or webcam plugged into your computer. Call all the libraries we need for this project Load the wav file you want to play on detection. The “haar cascade” xml files are needed to detect objects from the image. In this case, the kernels are tuned to detect the face and eyes of the person. The inference happens in an infinite while-loop that grabs a frame from the webcam feed, identifies the face and eyes, runs a classifier on the eyes, and then calculates a “drowsiness-score”. We can select a score threshold when a sound will be triggered. Effectively, the score will increase with closed eyes and is a measure for how long the eyes were closed. The threshold that has to be reached before sounding the alarm prevents the model from predicting simple blinking as drowsiness. Futhermore, both eyes need to be closed at the same time. When executing the next cell, a window with the video capture will pop up. Quit by hitting ‘q’. To re-start, open the video capture again (execute cell above). Cats Vs. Dogs computer vision with the TensorFlow API Given the somewhat mediocre performance of the previous model for Cats Vs Dogs, it seems warranted to implement new tools that promise performance gains. The classification model used previously suffered from overfitting. That means, the training set was learned very well, but probably so well, that the unknown data in the validation set could not be predicted precisely. If a model can only predict well what it has seen before means that it does not “generalize” well. To improve generalization on the Dogs Vs. Cats set, we can implement two extra measures. Transfer learning, image augmentation, and neuron dropout in some layers. Otherwise, we will keep the setup as before. If details are unclear, read up in Part I We will follow these steps: If you want to follow along on the Jupyter notebook hosted on GitHub click on this link, otherwise keep on reading. Transfer learning is a technique by which we can make use of learned weights of much larger networks. Such networks were trained on millions of images and many classes and are often available to download. What we will do is, download the learned weights of the Inception V3 network and add our own dense layers and outputs on top. Using the Inception V3 transfer learning enables us to “step on the shoulders of giants” and helps us identify shapes, objects etc. in the images we re-train it on afterwards. We are transferring the learned weights into our own network without the heavy training load of millions of images. Here, we will download the weights as an .h5 file. Next, we also have to set up the network itself as the authors of Inception V3 designed it. Luckily, keras has this model already built in in its library. We only have to import it and then fill in the weights from the .h5 file. While training on the cats vs. dogs images, we do NOT want to re-train the entire Inception V3 network. Hence, we set Let’s have a look at the layers of the pre-trained model: Result: In total, there are almost 100 layers of batch normalizations, 2d convolutions, activations etc. etc…. which makes ~ 22 million parameters. We will not use the original output of the network, but replace it with our own dense layers and output neurons. We will define the the last / output layer of the Inception network. Result: As mentioned beforek, we will have to define layers that are attached to the end of the Inception network and are trainable. Four layers will get added. First, a flatten layer that takes the 2d output of the Inception and unravels it into a 1d vector. Second, a trainable fully-connected layer. Third a droput layer, and fourth, an output layer with a single neuron as we had in Part I already. New is the droput. Droput layers are an additional tool for regularization and will delete random neurons. Many adjacent neurons are thought to be trained with similar values and contribute to overfitting. Setting the droput to 0.2 will make sure that 20% of all neurons in this layer will be canceled. The droput percentage is something to tweak. As in Part I, we have to download the Cats Vs. Dogs data set again and unzip it. As before, we define the train, validation, and paths to the two classes so we can feed them to the Image Data Generator and stream the files into the training process. Here, we will use new parameters for the ImageDataGenerator which will augment the images in the folder on-the-fly. On-the-fly means that the generator applies these augmentations during training without saving data to the hard drive. The modifications taking place are mainly distortions of existing images such as rotation, shearing, mirroring, lateral shifts, and zooms. In short, is a very handy way of vastly increasing the number of training examples without having to take more photos. Result: As previously, we pass the image generators for tain and validation to our model and start it! Result: Finally we can check what the new implemented tools did to improve the model by plotting the training history. Remember, in the old model Training Accuracy rose to almost 100% after 15 epochs, while the Validation Accuracy stagnated near ~70%. Result: In the new model, the Validation Accuracy (~95%) is even higher than the Training Accuracy (~90%). This is largely a success. Fine-tuning parameters such as the drop out rate and training epochs may be worth a try to modify. A visible trend in the history losses are increasing too. This means good predictions may be getting worse in higher epochs. Losses keep increasing faster than they are decreases. This remains an issue to be solved. Thanks to Lawrence Moroney (Google) by whom this project was inspired (link to notebook on Google CoLab) and Kaggle for their Cats Vs Dogs dataset. Cats Vs. Dogs computer vision with the TensorFlow API In a previous post about computer vision I wrote how to make binary predictions if a photo contains a cat or no cat Article “Cat Prediction”. This was a much simpler classifier built from ground up. However, not many users would still programm everything from scratch today. It is much easier to make use of a Deep Learning API such as PyTorch, Keras, TensorFlow etc. For this project, we will take that to the next level, recognizing real images of Cats and Dogs in order to classify an incoming image as one or the other using Google’s TensorFlow. This API has many functions already built in so that they only have to be called with a single line of code or even set only a parameter. For example, as part of the task we need to process the data - not least resizing it to be uniform in shape. We will follow these steps: If you want to follow along on the Jupyter notebook hosted on GitHub click on this link, otherwise keep on reading. Let’s start by downloading our example data, a .zip of 2,000 JPG pictures of cats and dogs, and extracting it locally in \Data . Note: The place where your Jupyter file is stored is the working directory. The 2,000 images used in this exercise are excerpted from the “Dogs vs. Cats” dataset available on Kaggle, which contains 25,000 images. Here, we use a subset of the full dataset to decrease training time for practial purposes. The following code will use the OS library to use Operating System libraries, giving you access to the working directory, and the zipfile library allowing you to unzip the data. The contents of the .zip are extracted to the base directory \Data\cats_and_dogs_filtered, which contains train and validation subdirectories for the training and validation datasets, which in turn each contain cats and dogs subdirectories. In Summary: The Training Set are the photos that are used to tell the model that this is what cats and dogs look like. The Validation Set contains images of cats and dogs that the model will not see as part of the training, so we can test how it does in evaluating if an image contains a cat or a dog. The practical thing about TensorFlow: We do not explicitly label the images as cats or dogs. We will use the ImageGenerator, which is used to read images from subdirectories, and automatically label the data contained with the name of that subdirectory. So we will have a ‘Training’ directory containing a ‘Cats’ directory and a ‘Dogs’ one. The ImageGenerator will label the images appropriately for us and saving us time. First we have to define the paths to all these directories: Now, let’s see what the file names look like in the cats and dogs train directories (file naming conventions are the same in the validation directory): Result: Let’s find out the total number of cat and dog images in the train and validation directories: Result: For both cats and dogs, we have 1,000 training images and 500 validation images. Now let’s take a look at a few pictures to get a better sense of what the cat and dog datasets look like. First, configure the matplot parameters: Now, display a batch of eight cat and eight dog pictures. Each time this code is called, a new set of pictures will appear. Result: The images are in color and come in a variety of shapes. Before training a Neural network with them we will need to tweak the images. We will see that in the next section. Ok, now that you have an idea for what your data looks like, the next step is to define the model that will be trained to recognize cats or dogs from these images. First of all, we need to import TensorFlow and best check for the installed version. This simple neural network will start with images of the size 150 x 150 pixels and three color values (RGB). It will contain three convolutional layers followed by pooling layers, which reduce the number of pixels. Then the 2D images will be flattened out to a single row of pixels that become neurons. After that, a fully connected layer (dense) with ReLu and then already the output layer with a single neuron that will indicate 1 or 0 for cat or dog. Activation for that final neuron will be a sigmoid function. The model layout can be shown by calling the summary method. Result: The “output shape” column shows how the size of the feature map evolves in each successive layer. The convolution layers reduce the size of the feature maps by a bit due to lack of padding, and each pooling layer halves the dimensions. Next, we will set more model configurations. We will train the model with the binary_crossentropy loss, because it is a binary classification problem (cat,dog) and our final activation is a sigmoid. We will use the rmsprop optimizer with a learning rate of 0.001. During training, we will want to monitor classification “accuracy”. Let’s configure the data generators that will read pictures in our source folders, convert them to float32 tensors, and feed them including labels to the neural network. Training images and validation images will be separate generators. The generators will yield batches of 20 images of size 150x150 and their labels (binary). Statistical modeling data should usually be normalized to make it more amenable to processing by the network. In our case, we will preprocess our images by normalizing the pixel values to be in the 0 to 1 range. Originally all values are in the 0 to 255 range. In Keras this can be done via the Let’s train on all 2,000 images available, for 15 epochs, and validate on all 1,000 test images. TensorFlow will print four metrics per epoch – Loss, Accuracy, Validation Loss and Validation Accuracy. The Loss and Accuracy are a great indication of progress of Training. It’s making a guess as to the classification of the training data, and then measuring it against the known label, calculating the result. Accuracy is the portion of correct guesses. The Validation Accuracy is the measurement with the data that has not been used in training. As expected this would be a bit lower. Result: To get a feel for what kind of features the convolutional network has learned, one fun thing to do is to visualize how an input gets transformed as it goes through the network. Let’s pick a random cat or dog image from the training set, and then generate a figure where each row is the output of a layer, and each image in the row is a specific filter in that output feature map. Rerun this cell to generate intermediate representations for a variety of training images. Result: Let’s now take a look at actually making predictions using the model. I chose five cat photos and five dog photos from https://unsplash.com/, and fed them to the model, giving an indication of whether the object is a dog (1) or a cat (0). Some of the photos are not as straight forward, since objects surrounding the animal are present, such as hands, leafs, larger background areas etc and may be relatively hard to classify. The photos are in the upload_cats_and_dogs folder and were re-named by me to indicate their contents. Since we are not using the image generator, we have to manually reduce the size to our model’s image processing size (150x150 pixels). Result: The pictures I uploaded were not predicted entirely correctly. All the dogs were correctly classified as “dog”, but only two out of five cats were classified “cat”. Let’s plot the Training/Validation accuracy and loss as collected during training: Result: As the graph above shows, we are strongly overfitting our Training Set. Our Training accuracy (in blue) gets close to 100%, while our Validation accuracy (in orange) stalls as ~71%. The validation loss reaches its minimum after only five epochs and then increases steadily. Since we have a relatively small number of training examples (2000), overfitting should be our greatest concern. Overfitting happens when a model exposed to too few examples learns patterns that do not generalize to new data, i.e., when the model starts using irrelevant features for making predictions. Overfitting is the central problem in machine learning: given that we are fitting the parameters of our model to a given dataset, how can we make sure that the representations learned by the model will be applicable to data never seen before? How do we avoid learning things that are specific to the training data? In the next post, I will look at ways to prevent overfitting in this classification model. Thanks to Lawrence Moroney (Google) by whom this project was inspired (link to notebook on Google CoLab) and Kaggle for their Cats Vs Dogs dataset. Reconstructing the Great Salt Lake’s giant ancestor The Western United States is home to several terminal lakes with no outflow and evaporite deposition such as carbonates and salts (Vennin et al., 2018, Harris et al., 2013). Approximately 15,000 years ago, lakes in the Great Basin of the western United States achieved their maximum late Pleistocene extents. Three of those lake systems stand out in terms of surface area: Lake Lahontan with a surface area of 22,300 km2, Lake Bonneville with a surface area of 51,300 km2, and Lake Missoula with 7,770 km2. These gigantic freshwater bodies, which had surface areas approximately 10 times their reconstructed mean-historical values, have been the subject of intensive scientific research since Russell’s seminal study of Lake Lahontan (Russell, 1885) and Gilbert’s seminal study of Lake Bonneville (Gilbert, 1890). Three main questions have occupied the minds of present-day paleoclimatologists working in these basins: (1) what caused the lakes to grow so large, (2) what was the record of lake-level change in each basin during the last glacial period, and (3) were lake-size changes linked to abrupt changes in the climate of the North Atlantic signaled by Dansgaard-Oeschgerand Heinrich events (Dansgaard, 1993). It is assumed that the ice shield covering North America during that period placed ground moraine dams on the lakes, which led them to grow in area and depth (Bond, 1993). Melting of the ice sheets “pulled the plug” and rapidly lowered water levels in the basin. Bonneville reached its highstand level at 18.6 ka; it fluctuated near that level until 17.5 ka, at which time it incised its threshold at Red Rock Pass, Idaho, reaching the spillover level named “Red Rock Pass level” at 17.4 ka. Multiple research groups dated paleo-shorelines of Lake Bonneville and corroborated dates of lake levels using sediment cores (e.g., Benson et al. 2011). This project’s goal is to explore the potential to use publicly Digital Elevation Models (DEMs) to calculate the water volumes in the Lake Bonneville system at different times during the last glacial. Specifically, it is to be answered whether spillover points and outflow locations can be detected using satellite imagery. a. What was the volume and area of glacial paleo-Lake Bonneville during different time intervals and how does it compare to the modern Great Salt Lake? How much of a difference in volume is represent by different shoreline levels? b. Where were the spillover points/dams for ancestral Lake Bonneville for shoreline levels at various heights? I will mainly use government-published GIS data for this project, which is a data source most reliable and best-documented. Optionally, the USGS also provides 10 m DEMs but at a much larger size of the dataset, which would make processing unwieldy (time and memory). The different ages and lake levels since the Late Pleistocene and historic times were gathered from the literature (Benson, 2011) and ARGC. As preparatory step, the ARGC feature containing the historic Great Salt Lake extents gets separated into four polygons. Then, the relevant DEM tiles are merged to a continuous raster. For each published elevation, the DEMs are clipped to the Bonneville Highstand extent, since the lake never extended beyond this area. This avoids inclusion of low-lying valleys outside the maximum extent. For each DEM, the elevations above lake level is set to null, which yields the extent and depth information of each lake in time. Following this, the DEMs are converted to a polygon feature, dissolved, and simplified. Using the tool Surface Volume and Zonal Statistics, detailed information about each extent is produced and merged. Based on surface area, volume, and time, fluxes as a time series are calculated on spreadsheet. Objective A: Volume and Area Literature review yields eight significant lake levels, four recognized from chronologically dated paleo shorelines in the Late Pleistocene, and four historic levels recorded by various types of technology available at the time (Figure 1). Lake volumes and surface area changed significantly during the time Late Pleistocene (Table 1). The water levels at Great Salt Lake were gauged since 1850 and on average sat at 1,283 m, with a maximum water depth of 6 m. During the Bonneville Highstand, the lake was up to 275 m deep. Table 1 Processing results Using the timing and the water volume data, the net water flux in and out of the lake was calculated (Figure 2). Major net influx occurred between 24 ka (Stansbury Oscillation) and 18.6 ka (Bonneville Highstand). The transitional periods after 17.5 ka are marked by outflow, most notably the flood event spilling over at Red Rock Pass, Idaho. The water level was stable at the Provo level between 17 and 15.2 ka, after which another rapid volume loss occurred. Coming to a halt at the level of the Gilbert shoreline (12.9 ka) relatively little volume loss occurred till modern day. Table 2 Flow rate comparison with similar modern waterfalls (Wikipedia, 2020) In summary, the lake changed in size massively and was significantly larger in surface area, volume, and water depth. During the Bonneville Highstand between 18.6 and 17.5 ka, the lake contained ~750 times the volume it does today and was at its deepest point ~45 times as deep compared to the historic average. During the great flood event following the Bonneville Highstand, 224 mm (0.224 m) were drained on average per year for a total of 0.5 kyrs (500 years) from the lake (Figure 3). This flow rate is a large number when compared for example with the current sea level rise of 3.3 mm per year (NASA, 2020). Proof of the flood event are deposited sediments north of Red Rock Pass draping the valleys and the Snake River Plain (Malde, 1968). Assuming that the majority of the water drained evenly and not evaporate this can be put in perspective by comparing with modern waterfalls (Table 2). However, some authors believe that the flood was much more intense and the lake reached Red Rock Pass-level within 0.1 kyrs (Oviatt, 1992), which would make the flood similar in scale to the Niagara Falls at the US/Canada border. Objective B: Spillover points/dams Bonneville reached its highstand level at 18.6 ka; it fluctuated near that level until 17.5 ka, at which time it incised its threshold. The location of the spillover point at Red Rock Pass, Idaho is apparent in the elevation data as a meandering incision in the glacial till sediments (Figure 4). Incision continued until the bedrock formation at Red Rock Pass was met. Red Rock Pass was likely the only spillover point of the lake as constrained by δ18O from sediment cores (Benson, 2011). Later decrease in water volume came about through a shift towards warmer temperatures and higher evaporation in the post glacial times. The results yielded detailed information on the Great Salt Lake and its ancient predecessors: The Great Salt Lake used to be significantly larger and saw periods of water-level rise and fall. With an influx of 1.26 km3/year and lake level rise of 180 m between 24 and 18.6 ka this transitional period was the only time recorded with net growth of the lake surface area. The lake level reached a maximum termed the “Bonneville Highstand” between 18.6 and 17.5 ka. The loss of 4,708.80 km3 between 17.5 and 17 ka is referred to as the Flood Event. Spilling through the Red Rock Pass, northeast of the lake in Idaho, the water level dropped 112 m at flowed at rates resembling modern waterfalls. Conservative estimates (slow drain over 0.5 kyrs) suggest a waterfall the size of the Murchison Falls (Nile, Uganda). Other estimates suggest a faster drainage in 0.1 kyrs, which means an outflow event similar to the size of the Niagara Falls (USA/Canada border). Between 17 and 15.2 ka the lake resided at the Provo shoreline, which is just below the bedrock level of the Red Rock Pass. The fall from the Provo level to the Gilbert level was a 145 m drop as a closed system. Likely causes are climate change coming out of the glacial such as warmer temperatures and melting glaciers. Decreased precipitation and increased evaporation resulted in a net loss of lake volume. From the Gilbert shoreline it was a 10 m drop to the historic Great Salt Lake levels. Water volume decreased slowly to a tenth. The historic Great Salt Lake had significant changes in water volume from 0.9 km3 (1,280 m elevation) to 23.7 km3 (1,285 m elevation). However, it is currently assumed that not climate exclusively influences the water level of the Great Salt Lake. Current studies making use of hydrological accounting to calculate the water balance of the basin suggest that human consumption such as by consuming streamwater before it replenishes the lake may be a major influence (Wurtsbaugh, 2017). Limitations of the dataset The USGS National Map 1-arc-second DEM is continuous and well updated. However, especially within the Great Salt Lake area the data seem inconsistent and not faithfully representing the bathymetry. This is visible through the rectangular blocks representing large parts of the bathymetry. This may be attributed to the difficulty for obtaining bathymetry data by boat from the in relatively shallow lake. The Utah Geological Survey and Utah Division of Forestry, Fire and State Land published a newer LIDAR dataset in 2016 (Link) covering the lake shores in 0.5 to 1 m resolution. However, this dataset spares out the submerged parts of the lake. This means that the volumes and depths for the historic lake extents may not be as accurate. Since the historic part is only a fraction of the ancient extents, this skew may be less significant for the reconstructions of these parameters. Interactive Map on ArcGIS Online Click “Open in Map Viewer” Quantify the Burned Forest Area in Australia Fires ravaged the forested south of Australia in the past dry season and made global headlines in January 2020. I chose to compare Landsat imagery of the Australian Alps from last Spring and Summer, i.e. pre and post fire to assess the area of burnt forest. The selected tile Path 91 Row 85 covers the southwestern corner of the Australian Capital Territory (ACT) and the New South Wales/Victoria territory border. To achieve such an analysis, ca. 10 time slices of Landsat 8 imagery were requested from USGS EarthExplorer covering September 2019 and April 2020. Many slices were discarded due to high cloud coverage, smoke, and haze that would make classification ambiguous. Selected time slices were 09 September 2019 (Spring / pre-burn) and 23 January 2020 (Summer / post-burn). In the following I show how to train a classification model that quantifies the burnt area. The nexts steps will have to be completed twice, once for each seasonal image. Step 1 Unpack the Landsat8 files and use the tool “Composite Bands” in ArcGIS that combines multiple wavelength band images into a single image. Landsat8’s band assignment can be taken from the metadata in each compressed file. Step 2 Create an NDVI raster. NDVI is an acronym for Normalized Difference Vegetation Index and uses the Red and the Near Infrared bands The burn scars in the mountains should be visible as broad areas of low NDVI, ranging from northwest to southeast. Step 3 Enable the “Image Classification” Toolbar. On the Image Classification Toolbar click on the Sample Manager (1). Here you can add polygons that represent color values of your classes (2) by clicking into the raster image. Add a minimum of 10 samples for each class you want to record to cover as much variability across the image as possible. In the forest fire case we should take samples of “Water” (lakes, rivers), “Open Land” (dirt, grassland etc.), “Healthy Forest”, “Burnt Forest” and if applicable “Snow” or “Clouds”. I suggest you do not classify towns and other human infrastructure, since it is harder to distinguish from other classes and beyond the scope of this project. When you are done, click “Merge Training Samples” (3), rename the class name, and select an intuitive color. The training samples of your first classification can potentially be reused in the second classification by clicking the “Load Training Samples” button, but make sure all classes are still well represented and make adjustments when necessary. Step 4 Next step is the assessment the samples. Ideally, all classes are well separated and do not have overlapping colors. Click on the Histogram and Scatterplot icons (1) and judge how much overlap exists. When you are satisfied with your work, save the classification shapes (2) and then train the model by clicking on “Create a Signature File” (3). Step 5 Using the signature file we can make predictions for the entire image in a classification raster. In the “Image Classification Toolbar” click “Classification”, in the menue then select the “Maximum Likelihood Classification” Tool. This new raster contains the count of cells for each class, but not the real area we want. So either add a field to the Attribute Table and use the “Field Calculator” (Landsat8 cells are 30 m edge length = 900 m2 per cell) or convert the classification raster to a feature, which pre-calculates the area values (“Raster to Polygon” tool, tick “multipart features”). No Burnt Forests were visible in September 2019’s NDVI, hence no training shapes were used for classifying Burnt Forests and it has to be assumed 0 km2 were charred. A total of 6250 km2 were measured in January 2020 few days to weeks after the forest fires in the selected Landsat8 imagery. The burnt forest areas of southeast Australia are reliably located using NDVI and quantified using the Maximum Likelihood Classification tool, which is a proof-of-concept. Future research may include: Automate the Boring Stuff Many tasks in ArcGIS can be tedious, time-consuming, and require repeated execution. Here I show how streamlines can be calculated from a DEM model that could for example have been created previously from LIDAR data (Part I). Series of different geoprocessing tools can be run automatically by stringing them together in the Model Builder, and save the Model for future execution. Building re-usable models for geoprocessing tasks will save time and eliminate human error. Any chain of tasks can be automated, however in the following we will build a DEM to Streamlines model step by step. Starting point is a DEM raster layer. The example I will use is a hydrologically conditioned DEM in which sinks that not exist in nature (bugs in the DEM) are filled, streams are “burned”, and ridges are “fenced”. See for information on this processing here in a slideshow by ESRI. Let’s get right into the creation of the streamlines with the Model Builder and create a new custom toolbox. Open the Geoprocessing pane called ArcToolbox (1). Right click on the top entry also called “ArcToolbox” (2) and then select “Add Toolbox” (3). The toolbox will be like a folder for models we will create soon. Select the folder you want to save the toolbox and then click the small icon of a red toolbox with a star in the top right corner (4) and give it a descriptive name such as “Hydrologic Tools”. Now we will add the newly created toolbox, hence repeat steps 1-3, select the new toolbox, and click “Open”. The “Hydrologic Tools” will now appear among with all the other ArcGIS built-in toolboxes. Great. Create the model. Right click on the new toolbox (1) and select “New” (2) and “Model” (3). Ignore the popup for a moment and close it we will get back to it in the next step. Right click on the new model (4) and then “Rename” (5) to change the name from the default to “DEM to Streamlines”. Everything is set now to get going. Double clicking will start the model like any other tool, but we first have to customoze our model. Hence, right click and click “Edit” and we are back at the empty Model Builder screen from last step. We will fill this empty screen with tools that we are going to chain together. The first process will be the “Flow Direction” tool, which creates a new raster flow direction from each cell to its downslope neighbors. Drag the “Flow Direction” tool rom the ArcToolbox into the Model Builder (“Spatial Analyst” and then “Hydrology”). Notice that tools are rectangular shapes and inputs / outputs are oval shapes. Not that in this state all the shapes are white. Double click on the “Flow Direction” tool to set Input Surface Raster to your DEM and then click OK. If everything went right, the tool will now be colored, which means it is ready to run. In future, we want that we can define the input raster for the model. To achieve that, we can right click on the Input oval and select “Model Parameter”. A little P should appear on the top right of the oval. Great. Next, let’s add the second tool, the “Flow Accumulation” tool, which is in the same sub-category as the “Flow Direction” tool before. Drag it into the Model Builder as before and drop it to the right of the “Flow Direction”. What does it do? It creates a raster of accumulated flow into each cell. Connecting the two can be done two ways: The first way is using the “Connect” tool (1) and first click on the previous output (2) and then on the “Flow Accumulation” box (3). Select Input Flow Direction Raster when the selection pops up. The second way to make the connection is by double clicking on the “Flow Accumulation” tool and selecting the FlowDir ouptput from the dropdown. If everything went right, all boxes should be colored once again. And do not worry about neatness in arranging the objects. We will use the Model Builder’s tidy-up feature in the end. In this step we are going to define how large the accumulation will be to generate a streamline based on a condition we define. Go in the ArcToolbox to “SpatialAnalyst”, “Conditional” and then “SetNull”. Again, drag it to the right hand side of the output and then connect the output to the tool shape in your preferred way. In the settings to “SetNull” we have two more things to define. First, the Expression, which is SQL based. Enter “Value < 100” without quotation marks. This expression is going to be evalued, and all accumulation values below 100 will be TRUE and set to null. Second under “Input false raster or constant value” set the Accumulation output raster. That means if the expression is evalued FALSE, and the value is larger than 100, the original value remains. Click OK, and all boxes should be colored again. The “SetNull” Expression we set in the previous step has larger influence on the Streamline length and how far they reach up into the mountains. Thus we want them to be a modifiable parameter in the model. However, if we simply made the entrie “SetNull” expression a Model Parameter, all the other settings would also appear. To make only the Expression available, we have to do something else. In the Model Builder top row, click “Insert”, “Create Variable”, and then “SQL Expression”. Connect the new object with the “SetNull” tool and enter into the “SQL Expression” what we had before “Value < 100”. Click “OK”. Lastly, right click on the “SQL Expression” and make it a “Model Parameter” so that the little P appears. In the this step we create a new object that assigns values to stream sections between intersections. Drag the tool named “Stream Links” from the Spatial Analyst, Hydrology toolbox into the Model Builder. Once in the builder we need to double click on the tool object to set two inputs. First, for “Input Stream Raster” select the output of the “SetNull” tool. Second, “Input flow direction raster”, select the “FlowDir” output from the first processing tool in the chain. Two arrows should now point at the “Stream Link” tool. The last processing tool will be the “Streams to Feature” tool, also in the same toolbox as the previous tools. This is going to be a real vector feature. “Stream to Feature” also needs two inputs. First: “Input Stream Raster” is going to be the “Stream Link” output. Second: “Input flow direction raster” is the output from the first tool, same as in the previous step. Click “OK”. The last output is what we our principal goal was. Rename the output by right cklicking and then “Rename…” to the new name “Stream Feature Output”. Since we want the model to be versatile and determine each time what the name of the last output is going to be, let’s make it a Model Parameter by right clicking and making the tick in the right place. Also it would be interesting to see the result without extra steps, so right click on the output again and make a tick at “Add To Display”. Finally, save the model We decide which intermediate outputs we want to store separately in the selected folder or (default) geodatabase. By default, all intermediate outputs are stored and nothing is lost. However, we can make the intermediates temporary by right clicking on the output ovals and selecting “Managed”. Cleaning up the Model Builder screen will help making the diagram look neat and easy to read. Click in icon row on the icon with the green and blue squares (1). We validate the model by having the Model Builder check if all the inputs, outputs, and options are set and taken care of by clicking on the little tick mark icon (2). Time to test the model. Click the “Play” icon to test-run the model (3). The tool currently processing will fill with red color and after completion it will receive a shadow effect. For testing and diagnosing of parts of the chain you can also select a tool and start the test-run from there. Click the tick icon (2) to reset the model and remove the shadows. If everything ran fine, delete the DEM path in the first input object on the left, so each time you start the model you do not have the path pre-populated. The coloration will fade except for the SQL statement. Time to save the model and close it. Time to run a real-world test of the model. Double click on “DEM to Streamlines” in the ArcToolbox, plug in your raster, modify the SQL Expression for accumulation control if you want to, define the output path and name for the streamlines feature, and then go have a coffee while the computer is working. Environmental analysis in ArcGIS Digital Elevation Models (DEMs) are often the most basic data available about the land surface elevation and are base for many following analysis products. DEMs come in form of greyscale raster files with the elevation (Z) direction encoded in the color value. From many parts of the world these DEM datasets are already available as georeferenced raster files. However, how are they generated? First step is recording point clouds through remote sensing techniques such as Light Detection and Ranging. The LIDAR sensor records a point where the laser is reflected from the ground together encoded elevation and spatial information. This reflection may come from a wall, a tree, water, roads, and so on. When mounted on a plane, LIDAR is a very convenient tool to get large numbers of sample points (clouds) symbolizing surface elevation. Let’s go through the steps of creating a DEM from LIDAR point clouds. State and federal agencies of many countries provide high-quality datasets that researchers and analysts can utilize for their purposes. Online portals present the coverage of such public dataset. For example: GISgeography.com “Top 6 Free LiDAR Data Sources”. I really like The Interagency Elevation Inventory for the U.S.A. Zoom to the location in the world where you need the data from. In my example, I will use two sections from the “USGS Lidar Point Cloud (LPC) CA_SanFranBay_2004” project. The important files to download are the .LAS and the metadata (.txt or .xml). Many larger LIDAR projects are subdivided into sections for easier downloading. Download and unzip all the required sections to a project folder. Open ArcMap and then click on the Catalog, browse to the project folder, right click on one of the .LAS and open the file properties. Check if the provider saved the coordinate system, projection, and measurement units to the .LAS file. If the field says “Unknown”, then information has to be added manually. Skip this step if your coordinate system and projection are saved in the .LAS properties. Adding the coordinate system and projection to the .LAS is not as straight forward as using the “Define Projection” tool for other features. Esri offers a separate toolbox on their website for creating a .PRJ file that contains the projection for each .LAS. Refer to this article for how to install and use the LAS Custom GP Tools for ArcGIS 10.2 toolbox that will generate .PRJ files. Make sure to follow the information given in the metadata exactly or else the point cloud may be some meters off in the best case or displayed on the other end of the world. Equipped with correct .PRJ we can run tool “Create LAS Dataset”. Click “Geoprocessing” and “Search For Tools”, then enter “Create LAS Dataset”. In the “Input Files” field select all the files or folders, define an output file name with meaningful name, and activate “Store Relative Paths”. Run the tool. Then drag the new .LASD file into the Layer on the screen to display it. Red bounding boxes should show the dimensions of the LAS sections in the LAS Dataset. If no LAS points are being rendered then the zoom is too far out. My two sections combined contain a total of 82,879,066 LAS points. Is the point cloud where it belongs in the world? We can check by comparing with a basemap. Click “Add Data”, “Add Basemap”. Which map design is up to you. If the basemap does not show, we need to set the Layer’s projection to “WGS 1984”, which is the correct one for ArcGIS’ online basempas. The LAS Dataset will be projected on-the-fly to the WGS 1984. If everything went right, the sections will be in the same place as seen on the online portal. When you zoom to the layer, it may happen that nothing is going to be displayed on the map except for the red bounding frames of the .LAS dataset(s). This may be if the datasets are so detailed that ArcGiS cannot display all of them at the same time. Nothing is wrong with the data itself. First, right click the .LAS dataset in the Table of Contents and click “Properties” and then “Display”. The point limit is by defailt at 800,000. You can increase to a maximum of 5,000,000 and click “OK”. If nothing is showing, try zooming into the extent. as soon as less than five million points are on the screen, they will be displayed. You may have to do a lot of zooming and the computer will be slow. Here is another approach: my .LAS dataset contains ~83 million points. That’s huge. Use the “Thin LAS” tool to create a new downsampled point cloud. It works on both .LAS and .LASD. Define your input .LAS(D), Target Folder, and name of the new .LASD (if you use a .LASD as input). For the Target XY Resolution and Target Z Resolution enter a reasonable number such as 1 m. Run the tool and new .LAS and .LASD files will be calculated. My new dataset consists now of ~25 million points. ##Step 7: Build a TIN Next, we create a Triangular Irregular Network (TIN), which is a 3D surface defined by nodes connected by triangles. This is an intermediate product on the way to the DEM. This method of DEM generation is nice because it is simple to understand and does not try to do anything to fancy. Return to “Search” to find the toolbox called “LAS Dataset To TIN”. Select your .LASD in the “Input LAS Dataset” input, select your project folder and name the new file accordingly. Alternatively, if you use only a single .LAS file, use the “Create TIN” tool. You may get the error “Too many points have been chosen to build a TIN. Either increase the amount of thinning or increase the maximum allowed output size”. In that case utilize the Thinning option, and Random Thinning Method. Try reducing the Thinning Value (in percent, 100 = no thinning) until the tool runs and creats a TIN. My new TIN was thinned to 10% and contains ~2.5 million nodes. The TIN is converted to a raster, the final product. Again, return to Search and type in “TIN to Raster”. Select the TIN for input, and specify ouptut folder and name. The option “Sampling Distance” will contain precalculated values for the resolution of the DEM. Try hardcoding the cellsize (in your map unit). Assess the DEM. The more detailed your TIN is, the smaller you can select the cellsize (DEM resolution) without introducing artefacts. Tweak the parameters (including the Output Raster name) in order to get your desired results. You should create a set of DEMs. Use the Image Analysis sidebar (from the Windows menu) to compare your different DEMs. Turn on the layers for two that you would want to compare, and use the Slider Tool (red arrow) to drag across the images and compare them. For the final product select the DEM with smallest cellsize and minimal artefacts. Note that the 1m-DEM contains many artefacts especially visible near the houses, which was introduced by reducing the TIN size down from the 1m LAS dataset. The 5m DEM is a better compromise. Is your Code going into the Freezer?

Introduction

What is the purpose of this badge and why did you receive it?

Source: GitHubHow did GitHub go about preparing your repo for eternity?

Source: GitHubWhat exactly does GitHub store in the Arctic World Archive?

Source: GitHub How to train your NLP chatbot. Spoiler... NLTK

Introduction
Scope of this chatbot

Prerequisites

Step 1: Imports
import nltk
from nltk.stem import WordNetLemmatizer
import pickle
import numpy as np
from keras.models import load_model
import json
import random
import os
lemmatizer = WordNetLemmatizer()
Step 2: Load Files
intents = json.loads(open(f'{os.getcwd()}\\Data\\chatbot_data\\intents.json').read())
words = pickle.load(open(f'{os.getcwd()}\\Data\\chatbot_data\\words.pkl','rb'))
classes = pickle.load(open(f'{os.getcwd()}\\Data\\chatbot_data\\classes.pkl','rb'))
model = load_model(f'{os.getcwd()}\\Data\\chatbot_data\\chatbot_model.h5')
Step 3: Preprocessing the input - Some helper functions
def clean_up_sentence(sentence):
# tokenize input pattern - split words into array
sentence_words = nltk.word_tokenize(sentence)
# stem each word - create short form for word
sentence_words = [lemmatizer.lemmatize(word.lower()) for word in sentence_words]
return sentence_words
# return bag of words array: 0 or 1 for each word in the bag that exists in the sentence
def bow(sentence, words, show_details=True):
# tokenize the pattern
sentence_words = clean_up_sentence(sentence)
# bag of words - matrix of N words, vocabulary matrix
bag = [0]*len(words)
for s in sentence_words:
for i,w in enumerate(words):
if w == s:
# assign 1 if current word is in the vocabulary position
bag[i] = 1
if show_details:
print ("found in bag: %s" % w)
return(np.array(bag))
def predict_class(sentence, model):
# filter out predictions below a threshold
p = bow(sentence, words,show_details=False)
res = model.predict(np.array([p]))[0]
ERROR_THRESHOLD = 0.25
results = [[i,r] for i,r in enumerate(res) if r>ERROR_THRESHOLD]
# sort by strength of probability
results.sort(key=lambda x: x[1], reverse=True)
return_list = []
for r in results:
return_list.append({"intent": classes[r[0]], "probability": str(r[1])})
return return_list
Step 4: Selecting a response
def getResponse(ints, intents_json):
tag = ints[0]['intent']
list_of_intents = intents_json['intents']
for i in list_of_intents:
if(i['tag']== tag):
result = random.choice(i['responses'])
break
return result
def chatbot_response(text):
ints = predict_class(text, model)
res = getResponse(ints, intents)
return res
Step 5: GUI

import tkinter
from tkinter import *
# send function: add entry to chat window and get chatbot response
def send():
# get written message and save to variable
msg = EntryBox.get("1.0",'end-1c').strip()
# remove message from entry box
EntryBox.delete("0.0",END)
if msg == "Message":
# if the user clicks send before entering their own message, "Message" gets inserted again
# no prediction/response
EntryBox.insert(END, "Message"
pass
# if user clicks send and proper entry
elif msg != '':
# activate chat window and insert message
ChatLog.config(state=NORMAL)
ChatLog.insert(END, "You: " + msg + '\n\n')
ChatLog.config(foreground="black", font=("Verdana", 12 ))
# insert bot response to chat window
res = chatbot_response(msg)
ChatLog.insert(END, "MedInfo: " + res + '\n\n')
# make window read-only again
ChatLog.config(state=DISABLED)
ChatLog.yview(END)
def clear_search(event):
EntryBox.delete("0.0",END)
EntryBox.config(foreground="black", font=("Verdana", 12))
Execute this Cell to start the chatbot GUI
base = Tk()
base.title("MedInfo")
base.geometry("400x500")
base.resizable(width=FALSE, height=FALSE)
# create chat window
ChatLog = Text(base, bd=0, bg="white", height="8", width="50", font="Arial",)
# initial greeting in chat window
ChatLog.config(foreground="black", font=("Verdana", 12 ))
ChatLog.insert(END, "MedInfo: Hello, I can help with... \n\t- Adverse Drug Reaction \n\t- Blood Pressure \n\t- Pharmacy Search \n\t- Hospital Search\n\n")
# disable window = read-only
ChatLog.config(state=DISABLED)
# bind scrollbar to ChatLog window
scrollbar = Scrollbar(base, command=ChatLog.yview, cursor="heart")
ChatLog['yscrollcommand'] = scrollbar.set
# create Button to send message
SendButton = Button(base, font=("Verdana",12,'bold'), text="Send", width="9", height=5,
bd=0, bg="blue", activebackground="gold",fg='#ffffff',
command= send )
# create the box to enter message
EntryBox = Text(base, bd=0, bg="white",width="29", height="5", font="Arial")
# display a grey text in EntryBox that's removed upon clicking or tab focus
EntryBox.insert(END, "Message")
EntryBox.config(foreground="grey", font=("Verdana", 12))
EntryBox.bind("<Button-1>", clear_search)
EntryBox.bind("<FocusIn>", clear_search)
# place components at given coordinates in window (x=0 y=0 top left corner)
scrollbar.place(x=376,y=6, height=386)
ChatLog.place(x=6,y=6, height=386, width=370)
EntryBox.place(x=6, y=401, height=90, width=265)
SendButton.place(x=282, y=401, height=90)
base.mainloop()
Falling Asleep? Detect Closed Eyes in Real Time

Introduction
Prerequisites (I prepared this in advance)
Imports
import cv2
import os
from keras.models import load_model
import numpy as np
from pygame import mixer
Alarm Setup
mixer.init()
sound = mixer.Sound(f'{os.getcwd()}\\Data\\drowsiness_data\\Electronic_Chime-KevanGC-495939803.wav')
sound.play()
Load OpenCV Haar kernels used to detect facial landmarks
face = cv2.CascadeClassifier(f'{os.getcwd()}\\Data\\drowsiness_data\\haarcascade_frontalface_alt.xml')
leye = cv2.CascadeClassifier(f'{os.getcwd()}\\Data\\drowsiness_data\\haarcascade_lefteye_2splits.xml')
reye = cv2.CascadeClassifier(f'{os.getcwd()}\\Data\\drowsiness_data\\haarcascade_righteye_2splits.xml')
Load the CNN model and start video stream
model = load_model(f'{os.getcwd()}\\Data\\drowsiness_data\\cnncat2.h5')
path = os.getcwd()
# Capture accesses the video feed. The "0" is the number of your video device, in case you have multiple.
cap = cv2.VideoCapture(0)
if cap.isOpened() == True:
print("Video stream open.")
else:
print("Problem opening video stream.")
font = cv2.FONT_HERSHEY_COMPLEX_SMALL
# starting value for closed-eyes inferences
score = 0
threshold = 6
thicc = 2
rpred = [99]
lpred = [99]
Start prediction cycle
# Infinite loop of capturing, infering, and scoring
while(True):
ret, frame = cap.read()
height,width = frame.shape[:2]
# convert frame to grayscale
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Apply Haar Cascade object detection in OpenCV to gray frame
faces = face.detectMultiScale(gray,minNeighbors=5,scaleFactor=1.1,minSize=(25,25))
left_eye = leye.detectMultiScale(gray)
right_eye = reye.detectMultiScale(gray)
# draw black bars top and bottom
cv2.rectangle(frame, (0,height-50) , (width,height) , (0,0,0) , thickness=cv2.FILLED )
# draw face box
for (x,y,w,h) in faces:
cv2.rectangle(frame, (x,y) , (x+w,y+h) , (100,100,100) , 1 )
# take detected RIGHT eye, preprocess and make CNN prediction
for (x,y,w,h) in right_eye:
r_eye = frame[y:y+h,x:x+w]
r_eye = cv2.cvtColor(r_eye,cv2.COLOR_BGR2GRAY)
r_eye = cv2.resize(r_eye,(24,24))
r_eye = r_eye/255
r_eye = r_eye.reshape(24,24,-1)
r_eye = np.expand_dims(r_eye,axis=0)
rpred = model.predict_classes(r_eye)
break
# take detected LEFT eye, preprocess and make CNN prediction
for (x,y,w,h) in left_eye:
l_eye = frame[y:y+h,x:x+w]
l_eye = cv2.cvtColor(l_eye,cv2.COLOR_BGR2GRAY)
l_eye = cv2.resize(l_eye,(24,24))
l_eye = l_eye/255
l_eye =l_eye.reshape(24,24,-1)
l_eye = np.expand_dims(l_eye,axis=0)
lpred = model.predict_classes(l_eye)
break
# labeling for frame, if BOTH eyes close, print CLOSED and adding/subtracting from score tally
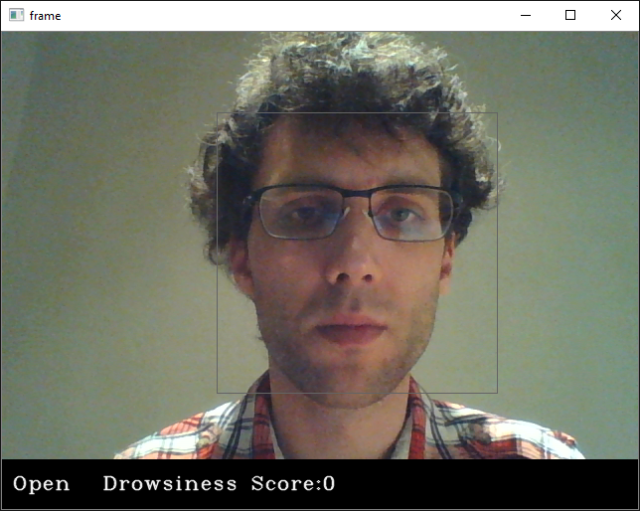
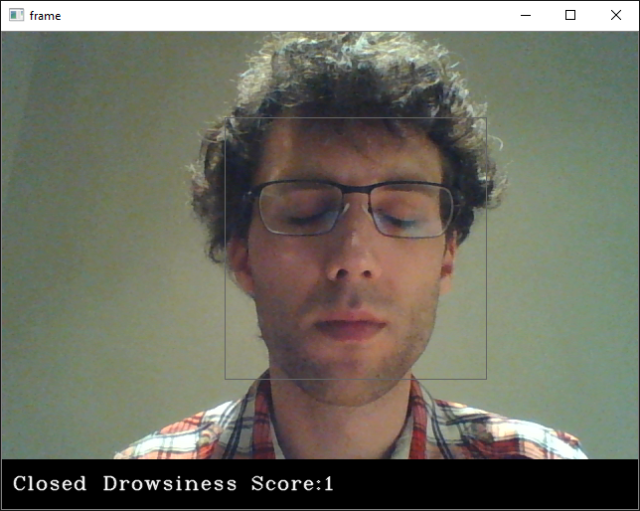
if(rpred[0]==0 and lpred[0]==0):
score += 1
cv2.putText(frame,"Closed",(10,height-20), font, 1,(255,255,255),1,cv2.LINE_AA)
# prevent a runaway score beyond threshold
if score > threshold + 1:
score = threshold
else:
score -= 1
cv2.putText(frame,"Open",(10,height-20), font, 1,(255,255,255),1,cv2.LINE_AA)
# SCORE HANDLING
# print current score to screen
if(score < 0):
score = 0
cv2.putText(frame,'Drowsiness Score:'+str(score),(100,height-20), font, 1,(255,255,255),1,cv2.LINE_AA)
# threshold exceedance
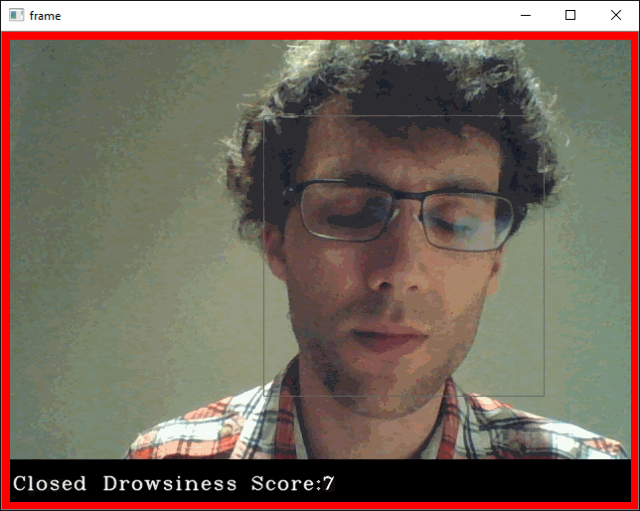
if(score>threshold):
# save a frame when threshold exceeded and play sound
cv2.imwrite(os.path.join(path,'closed_eyes_screencap.jpg'),frame)
try:
sound.play()
except: # isplaying = False
pass
# add red box as warning signal and make box thicker
if(thicc<16):
thicc += 2
# make box thinner again, to give it a pulsating appearance
else:
thicc -= 2
if(thicc<2):
thicc=2
cv2.rectangle(frame, (0,0), (width,height), (0,0,255), thickness=thicc)
# draw frame with all the stuff with have added
cv2.imshow('frame',frame)
# break the infinite loop when pressing q
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# close stream capture and close window
cap.release()
cv2.destroyAllWindows()
Result


Cats vs. Dogs in TensorFlow Part II

Introduction
Step 1: Transfer Learning
import os
import wget
url = 'https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
wget.download(url, out=f'{os.getcwd()}\\Data\\inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5')
layer.trainable = Falsefrom tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.applications.inception_v3 import InceptionV3
# all the weights for the trained Inception V3
local_weights_file = f'{os.getcwd()}\\Data\\inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
# the network shape of Inception V3 is integraded in Keras
pre_trained_model = InceptionV3(input_shape = (150, 150, 3),
include_top = False,
weights = None)
# combine layout and weights
pre_trained_model.load_weights(local_weights_file)
# make pre-trained model read-only
for layer in pre_trained_model.layers:
layer.trainable = False
# the Inception V3 is very deep
pre_trained_model.summary()
Model: "inception_v3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 150, 150, 3) 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 74, 74, 32) 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 74, 74, 32) 96 conv2d[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 74, 74, 32) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 32) 9216 activation[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 72, 72, 32) 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 72, 72, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18432 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 72, 72, 64) 192 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 72, 72, 64) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 35, 35, 64) 0 activation_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 35, 35, 80) 5120 max_pooling2d[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 35, 35, 80) 240 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 35, 35, 80) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 33, 33, 192) 138240 activation_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 33, 33, 192) 576 conv2d_4[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 33, 33, 192) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 16, 16, 192) 0 activation_4[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 64) 12288 max_pooling2d_1[0][0]
.
.
.
.
.
.
.
.
==================================================================================================
Total params: 21,802,784
Trainable params: 0
Non-trainable params: 21,802,784
__________________________________________________________________________________________________
# set layer "mixed 7" as end of pre-trained network
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output_shape)
last_output = last_layer.output
last layer output shape: (None, 7, 7, 768)
Step 2: Define Trainable Layers
from tensorflow.keras.optimizers import RMSprop
# Flatten the output layer to 1 dimension
x = layers.Flatten()(last_output)
# Add a fully connected layer with 1,024 hidden units and ReLU activation
x = layers.Dense(1024, activation='relu')(x)
# Add a dropout rate of 0.2
x = layers.Dropout(0.2)(x)
# Add a final sigmoid layer for classification
x = layers.Dense (1, activation='sigmoid')(x)
model = Model( pre_trained_model.input, x)
model.compile(optimizer = RMSprop(lr=0.0001),
loss = 'binary_crossentropy',
metrics = ['accuracy'])
Step 3: Download Dataset
url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
wget.download(url, out=f'{os.getcwd()}\\Data\\cats_and_dogs_filtered.zip')
import zipfile
local_zip = f'{os.getcwd()}\\Data\\cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall(f'{os.getcwd()}\\Data')
zip_ref.close()
Step 4: Pre-Processing - Image Data Generator and Image Augmentation
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Define our example directories and files
base_dir = f'{os.getcwd()}\\Data\\cats_and_dogs_filtered'
# create directory names
train_dir = os.path.join( base_dir, 'train')
validation_dir = os.path.join( base_dir, 'validation')
train_cats_dir = os.path.join(train_dir, 'cats') # Directory with our training cat pictures
train_dogs_dir = os.path.join(train_dir, 'dogs') # Directory with our training dog pictures
validation_cats_dir = os.path.join(validation_dir, 'cats') # Directory with our validation cat pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')# Directory with our validation dog pictures
# get all training file names
train_cat_fnames = os.listdir(train_cats_dir)
train_dog_fnames = os.listdir(train_dogs_dir)
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255.,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size = 20,
class_mode = 'binary',
target_size = (150, 150))
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory( validation_dir,
batch_size = 20,
class_mode = 'binary',
target_size = (150, 150))
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Step 5: Train Model
history = model.fit(
train_generator,
validation_data = validation_generator,
steps_per_epoch = 100,
epochs = 20,
validation_steps = 50,
verbose = 2)
Epoch 1/20
100/100 - 27s - loss: 0.4954 - accuracy: 0.7655 - val_loss: 0.6056 - val_accuracy: 0.8500
Epoch 2/20
100/100 - 15s - loss: 0.3829 - accuracy: 0.8315 - val_loss: 0.2152 - val_accuracy: 0.9440
Epoch 3/20
100/100 - 15s - loss: 0.3400 - accuracy: 0.8505 - val_loss: 0.2933 - val_accuracy: 0.9360
Epoch 4/20
100/100 - 15s - loss: 0.3316 - accuracy: 0.8625 - val_loss: 0.1953 - val_accuracy: 0.9570
Epoch 5/20
100/100 - 16s - loss: 0.3227 - accuracy: 0.8615 - val_loss: 0.3282 - val_accuracy: 0.9470
Epoch 6/20
100/100 - 16s - loss: 0.3226 - accuracy: 0.8585 - val_loss: 0.3156 - val_accuracy: 0.9530
Epoch 7/20
100/100 - 15s - loss: 0.3046 - accuracy: 0.8700 - val_loss: 0.3480 - val_accuracy: 0.9470
Epoch 8/20
100/100 - 15s - loss: 0.2785 - accuracy: 0.8750 - val_loss: 0.4184 - val_accuracy: 0.9450
Epoch 9/20
100/100 - 15s - loss: 0.2843 - accuracy: 0.8815 - val_loss: 0.3369 - val_accuracy: 0.9500
Epoch 10/20
100/100 - 15s - loss: 0.2957 - accuracy: 0.8800 - val_loss: 0.4547 - val_accuracy: 0.9430
Epoch 11/20
100/100 - 15s - loss: 0.2685 - accuracy: 0.8970 - val_loss: 0.3231 - val_accuracy: 0.9470
Epoch 12/20
100/100 - 15s - loss: 0.2551 - accuracy: 0.8955 - val_loss: 0.4682 - val_accuracy: 0.9480
Epoch 13/20
100/100 - 16s - loss: 0.2701 - accuracy: 0.8935 - val_loss: 0.3559 - val_accuracy: 0.9540
Epoch 14/20
100/100 - 18s - loss: 0.2842 - accuracy: 0.8865 - val_loss: 0.4018 - val_accuracy: 0.9470
Epoch 15/20
100/100 - 17s - loss: 0.2458 - accuracy: 0.9025 - val_loss: 0.4076 - val_accuracy: 0.9550
Epoch 16/20
100/100 - 16s - loss: 0.2533 - accuracy: 0.9025 - val_loss: 0.3737 - val_accuracy: 0.9620
Epoch 17/20
100/100 - 15s - loss: 0.2465 - accuracy: 0.9080 - val_loss: 0.3398 - val_accuracy: 0.9650
Epoch 18/20
100/100 - 15s - loss: 0.2620 - accuracy: 0.8925 - val_loss: 0.3271 - val_accuracy: 0.9640
Epoch 19/20
100/100 - 15s - loss: 0.2321 - accuracy: 0.9060 - val_loss: 0.3551 - val_accuracy: 0.9670
Epoch 20/20
100/100 - 15s - loss: 0.2470 - accuracy: 0.9000 - val_loss: 0.4488 - val_accuracy: 0.9500
Step 6: Evaluate the Training and Validation Accuracy
from matplotlib import pyplot as plt
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc = history.history[ 'accuracy' ]
val_acc = history.history[ 'val_accuracy' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot ( epochs, acc, label='Training Accuracy' )
plt.plot ( epochs, val_acc, label='Validation Accuracy' )
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.title ('Training and validation accuracy')
plt.figure()
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot ( epochs, loss, label='Training Loss' )
plt.plot ( epochs, val_loss, label='Validation Loss' )
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
plt.title ('Training and validation loss' )

Acknowledgements:
Cats vs. Dogs in TensorFlow Part I

Introduction
Step 1: Explore the Example Data of Cats and Dogs
import os
import wget
url = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
wget.download(url, out=f'{os.getcwd()}\\Data\\cats_and_dogs_filtered.zip')
import zipfile
local_zip = f'{os.getcwd()}\\Data\\cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall(f'{os.getcwd()}\\Data')
zip_ref.close()
base_dir = f'{os.getcwd()}\\Data\\cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat/dog pictures
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat/dog pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
train_cat_fnames = os.listdir( train_cats_dir )
train_dog_fnames = os.listdir( train_dogs_dir )
print(train_cat_fnames[:10])
print(train_dog_fnames[:10])
['cat.0.jpg', 'cat.1.jpg', 'cat.10.jpg', 'cat.100.jpg', 'cat.101.jpg', 'cat.102.jpg', 'cat.103.jpg', 'cat.104.jpg', 'cat.105.jpg', 'cat.106.jpg']
['dog.0.jpg', 'dog.1.jpg', 'dog.10.jpg', 'dog.100.jpg', 'dog.101.jpg', 'dog.102.jpg', 'dog.103.jpg', 'dog.104.jpg', 'dog.105.jpg', 'dog.106.jpg']
print('total training cat images :', len(os.listdir( train_cats_dir ) ))
print('total training dog images :', len(os.listdir( train_dogs_dir ) ))
print('total validation cat images :', len(os.listdir( validation_cats_dir ) ))
print('total validation dog images :', len(os.listdir( validation_dogs_dir ) ))
total training cat images : 1000
total training dog images : 1000
total validation cat images : 500
total validation dog images : 500
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
# Parameters for our graph; we'll output images in a 4x4 configuration
nrows = 4
ncols = 4
pic_index = 0 # Index for iterating over images
# Set up matplotlib fig, and size it to fit 4x4 pics
fig = plt.gcf()
fig.set_size_inches(ncols*4, nrows*4)
pic_index+=8
next_cat_pix = [os.path.join(train_cats_dir, fname)
for fname in train_cat_fnames[ pic_index-8:pic_index]
]
next_dog_pix = [os.path.join(train_dogs_dir, fname)
for fname in train_dog_fnames[ pic_index-8:pic_index]
]
for i, img_path in enumerate(next_cat_pix+next_dog_pix):
# Set up subplot; subplot indices start at 1
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off') # Don't show axes (or gridlines)
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()

Step 2: Build a Convolutional Neural Network
import tensorflow as tf
print("TensorFlow version: ",tf.__version__)
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image 150x150 with 3 bytes color
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
# Only 1 output neuron. It will contain a value from 0-1 where 0 for 1 class ('cats') and 1 for the other ('dogs')
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 18496) 0
_________________________________________________________________
dense (Dense) (None, 512) 9470464
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 9,494,561
Trainable params: 9,494,561
Non-trainable params: 0
__________________________
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics = ['accuracy'])
Step 3: Pre-Processing - Image Data Generator
keras.preprocessing.image.ImageDataGenerator class using the rescale parameter. This ImageDataGenerator class allows you to instantiate generators of augmented image batches (and their labels) via .flow(data, labels) or .flow_from_directory(directory). These generators can then be used with the Keras model methods that accept data generators as inputs: fit, evaluate_generator, and predict_generator.from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255.
train_datagen = ImageDataGenerator( rescale = 1.0/255. )
test_datagen = ImageDataGenerator( rescale = 1.0/255. )
# --------------------
# Flow training images in batches of 20 using train_datagen generator
# --------------------
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=20,
class_mode='binary',
target_size=(150, 150))
# --------------------
# Flow validation images in batches of 20 using test_datagen generator
# --------------------
validation_generator = test_datagen.flow_from_directory(validation_dir,
batch_size=20,
class_mode = 'binary',
target_size = (150, 150))
Step 4: Training
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=100,
epochs=15,
validation_steps=50,
verbose=2)
Epoch 1/15
100/100 - 17s - loss: 0.7927 - accuracy: 0.5525 - val_loss: 0.6704 - val_accuracy: 0.6120
Epoch 2/15
100/100 - 7s - loss: 0.6163 - accuracy: 0.6635 - val_loss: 0.6668 - val_accuracy: 0.6150
Epoch 3/15
100/100 - 7s - loss: 0.5260 - accuracy: 0.7415 - val_loss: 0.5673 - val_accuracy: 0.7150
Epoch 4/15
100/100 - 7s - loss: 0.4682 - accuracy: 0.7745 - val_loss: 0.5919 - val_accuracy: 0.7070
Epoch 5/15
100/100 - 7s - loss: 0.3799 - accuracy: 0.8245 - val_loss: 0.5949 - val_accuracy: 0.7080
Epoch 6/15
100/100 - 7s - loss: 0.2923 - accuracy: 0.8705 - val_loss: 0.6991 - val_accuracy: 0.7180
Epoch 7/15
100/100 - 7s - loss: 0.2027 - accuracy: 0.9250 - val_loss: 0.8081 - val_accuracy: 0.7170
Epoch 8/15
100/100 - 7s - loss: 0.1384 - accuracy: 0.9460 - val_loss: 1.1282 - val_accuracy: 0.6960
Epoch 9/15
100/100 - 7s - loss: 0.1163 - accuracy: 0.9585 - val_loss: 1.0216 - val_accuracy: 0.7030
Epoch 10/15
100/100 - 7s - loss: 0.0761 - accuracy: 0.9735 - val_loss: 1.4962 - val_accuracy: 0.7060
Epoch 11/15
100/100 - 8s - loss: 0.0565 - accuracy: 0.9825 - val_loss: 1.3429 - val_accuracy: 0.7210
Epoch 12/15
100/100 - 7s - loss: 0.0486 - accuracy: 0.9835 - val_loss: 1.5935 - val_accuracy: 0.7040
Epoch 13/15
100/100 - 7s - loss: 0.0420 - accuracy: 0.9850 - val_loss: 1.4677 - val_accuracy: 0.7290
Epoch 14/15
100/100 - 7s - loss: 0.0469 - accuracy: 0.9855 - val_loss: 1.7934 - val_accuracy: 0.7110
Epoch 15/15
100/100 - 7s - loss: 0.0430 - accuracy: 0.9890 - val_loss: 2.0219 - val_accuracy: 0.7080
Step 5: Visualizing Intermediate Representations (Optional)
import numpy as np
import random
from tensorflow.keras.preprocessing.image import img_to_array, load_img
# Let's define a new Model that will take an image as input, and will output
# intermediate representations for all layers in the previous model after
# the first.
successive_outputs = [layer.output for layer in model.layers[1:]]
#visualization_model = Model(img_input, successive_outputs)
visualization_model = tf.keras.models.Model(inputs = model.input, outputs = successive_outputs)
# Let's prepare a random input image of a cat or dog from the training set.
cat_img_files = [os.path.join(train_cats_dir, f) for f in train_cat_fnames]
dog_img_files = [os.path.join(train_dogs_dir, f) for f in train_dog_fnames]
img_path = random.choice(cat_img_files + dog_img_files)
img = load_img(img_path, target_size=(150, 150)) # this is a PIL image
x = img_to_array(img) # Numpy array with shape (150, 150, 3)
x = x.reshape((1,) + x.shape) # Numpy array with shape (1, 150, 150, 3)
# Rescale by 1/255
x /= 255.0
# Let's run our image through our network, thus obtaining all
# intermediate representations for this image.
successive_feature_maps = visualization_model.predict(x)
# These are the names of the layers, so can have them as part of our plot
layer_names = [layer.name for layer in model.layers]
# -----------------------------------------------------------------------
# Now let's display our representations
# -----------------------------------------------------------------------
for layer_name, feature_map in zip(layer_names, successive_feature_maps):
if len(feature_map.shape) == 4:
#-------------------------------------------
# Just do this for the conv / maxpool layers, not the fully-connected layers
#-------------------------------------------
n_features = feature_map.shape[-1] # number of features in the feature map
size = feature_map.shape[ 1] # feature map shape (1, size, size, n_features)
# We will tile our images in this matrix
display_grid = np.zeros((size, size * n_features))
#-------------------------------------------------
# Postprocess the feature to be visually palatable
#-------------------------------------------------
for i in range(n_features):
x = feature_map[0, :, :, i]
x -= x.mean()
x /= x.std ()
x *= 64
x += 128
x = np.clip(x, 0, 255).astype('uint8')
display_grid[:, i * size : (i + 1) * size] = x # Tile each filter into a horizontal grid
#-----------------
# Display the grid
#-----------------
scale = 20. / n_features
plt.figure( figsize=(scale * n_features, scale) )
plt.title ( layer_name )
plt.grid ( False )
plt.imshow( display_grid, aspect='auto', cmap='viridis' )

Step 6: Making predictions

import numpy as np
from keras.preprocessing import image
#uploaded = files.upload()
uploaded_filenames = os.listdir(f'{os.getcwd()}\\Data\\upload_cats_and_dogs\\')
for fn in uploaded_filenames:
# predicting images
path = os.getcwd() + '\\Data\\upload_cats_and_dogs\\' + fn
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0:
print(fn + " is a dog")
else:
print(fn + " is a cat")
[0.]
cat_bamboo.jpg is a cat (correct)
[1.]
cat_bandana.jpg is a dog (false)
[0.]
cat_hand.jpg is a cat (correct)
[1.]
cat_leafs.jpg is a dog (false)
[1.]
dog_branch.jpg is a dog (correct)
[2.29507e-14]
dog_carwindow.jpg is a dog (correct)
[1.]
dog_forest.jpg is a dog (correct)
[1.]
dog_paddleboard.jpg is a dog (correct)
[1.]
dog_pughat.jpg is a dog (correct)
[1.]
kittens_basket.jpg is a dog (false)
Step 7: Evaluate the Training and Validation accuracy
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc = history.history[ 'accuracy' ]
val_acc = history.history[ 'val_accuracy' ]
loss = history.history[ 'loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot ( epochs, acc )
plt.plot ( epochs, val_acc )
plt.title ('Training and validation accuracy')
plt.figure()
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot ( epochs, loss )
plt.plot ( epochs, val_loss )
plt.title ('Training and validation loss' )

Acknowledgements:
How big was paleo Lake Bonneville?

Introduction
Objectives
Data Sources
Methods
Results

Figure 1 Extent of paleo lake levels recorded as shorelines and historic levels using gauges since 1850 (see Table 1).
Name (elevation) Time (ka) Surface (km2) Volume (km3) Max. Depth (m) Stansbury Oscillation (1,372 m) 25 – 24 25,824.7 1,798.7 95 Bonneville Highstand (1,552 m) 18.6 – 17.5 49,030.4 8,601.6 275 Provo (1,440 m) 17 – 15.2 35,031.8 3,892.8 163 Gilbert (1,295 m) 12.9 – 11.6 15,216.1 143.9 18 Great Salt Lake (1,285 m) historic 6,471.0 23.7 8 Great Salt Lake (1,283 m) hist. avg. historic 5,154.8 11.5 6 Great Salt Lake (1,282 m) historic 4,758.7 6.7 5 Great Salt Lake (1,280 m) historic 1,445.6 0.9 3

Figure 2 Water level above sea level.
km3/a m3/a m3/s Niagara Falls 75.91 75,907,152,000 2,407 Bonneville Highstand Flood Event (0.1 kyrs) 47.09 47,088,000,000 1,493 Great Falls (Virginia, USA) 14.95 14,948,064,000 474 Bonneville Highstand Flood Event (0.5 kyrs) 9.42 9,417,600,000 299 Murchison Falls (Uganda) 9.46 9,460,800,000 300 Alexandra Falls (NW Territories, Canada) 8.89 8,893,152,000 282

Figure 3 Net water flux between stable lake levels.

Figure 4 The spillover point at Red Rock Pass. After the erosion of the sediment dam, which caused the Flood Event at 17.5 ka, the lake receded to the Provo level.
Discussion
References
Additional Media

Landsat Imagery Classification

Introduction
Analysis
Red = Band 4, Green = Band 3, Blue = Band 2.

NDVI = (NIR - Red)/(NIR + Red). Higher values of the index indicate light reflected by vegetation, low values indicate the absence of vegetation. We could use the Raster Calculator, but ArcGIS has an integrated feature for quck and reliable creaton of such a raster. Activate the “Image Analysis” from the “Windows” menue. Click on the little leaf icon. Assess the image and if you want, change the color ramp. For example from red to green and add some transparency.








Results

Conclusions
NBR = (NIR - SWIR) / (NIR + SWIR). This proof-of-concept study confirms that classification can be feasible and automated using the Model Builder. DEM to Streamlines using the Model Builder
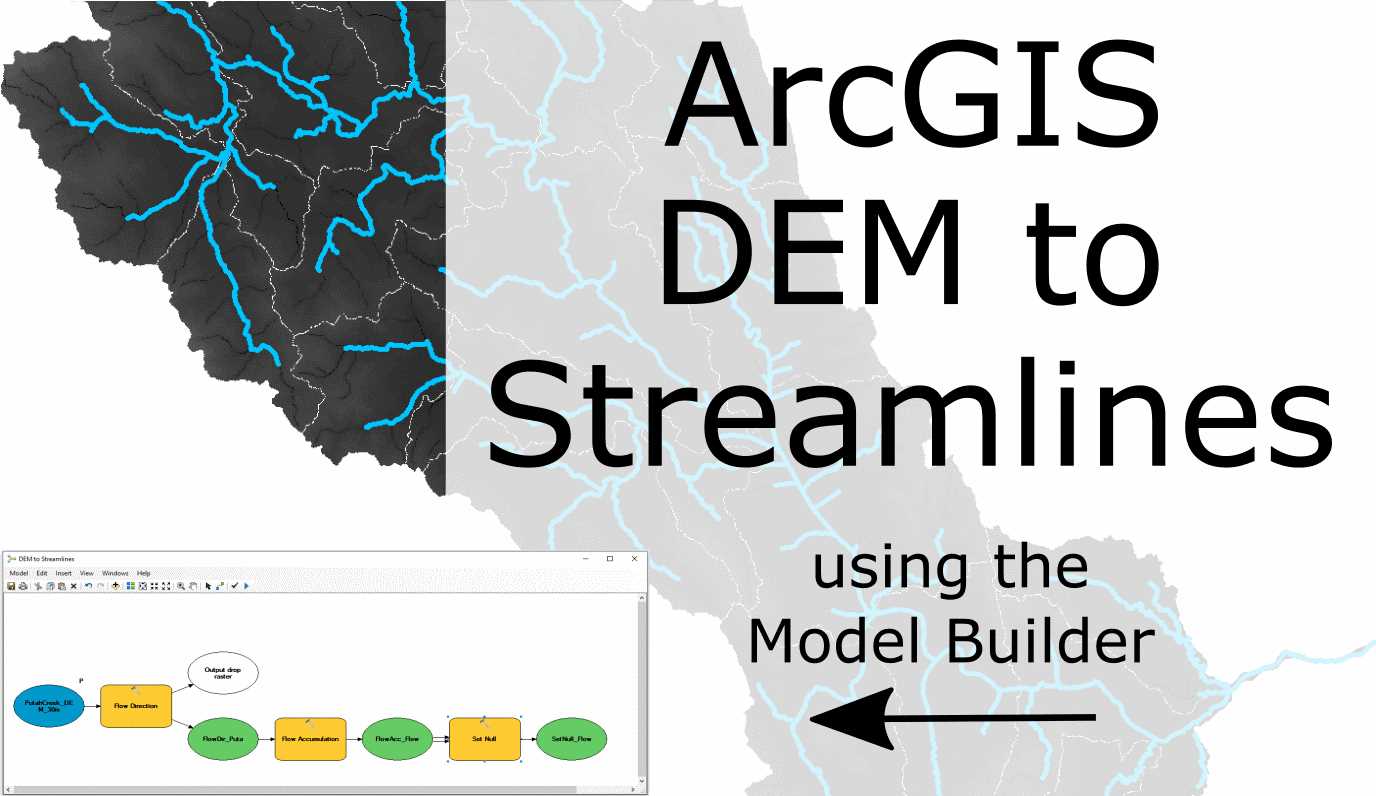
Introduction
Step 1: New Toolbox


Step 2: New Model


Step 3: Raster Flow Direction



Step 4: Flow Accumulation


Step 5: Generating Streamlines


Step 6: Add SQL Expression


Step 7: Stream Link


Step 8: Create a Feature


Step 9: Finishing Touches and Trial Run


Step 10: Validation

LIDAR to Digtital Elevation Models

Introduction
Step 1: Data Sourcing

Step 2: Loading

Step 3: Coordinate System

Step 4: Create LAS Dataset

Step 5: Assure geolocation

Step 6: Display Threshold



Step 8: Convert to Raster/DEM

Step 9: Find the right DEM Resolution

Step 10: Compare Multipe DEMs


Pagination